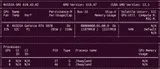
Ollama is building an engine for Apple and renting one for NVIDIA
Across the entire Ollama 0.30 line, the bespoke engine work went to Apple Silicon while NVIDIA rode upstream llama.cpp. The split is structural, and it changes which repo discrete-GPU users should actually be watching.